One of the most common tech questions when using WordPress, in my opinion, would have to be “What’s the correct way to set robots.txt in WordPress?” I wondered this same thing when I was configuring and testing things.
To know how to configure it, you first need to know what it is. Robots.txt is like enforcing laws on your server set for crawlers. For example, when Google is going to crawl your site they check this file and see what they can and cannot crawl. That’s basically it, you say open or closed.
I have done quite a bit of research on this topic. I started out checking the source, which in this case is WordPress. They show a great example of a robots.txt file that works well.
Sitemap: http://www.example.com/sitemap.xml
# Google Image
User-agent: Googlebot-Image
Disallow:
Allow: /*# Google AdSense
User-agent: Mediapartners-Google
Disallow:# digg mirror
User-agent: duggmirror
Disallow: /# global
User-agent: *
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/cache/
Disallow: /wp-content/themes/
Disallow: /trackback/
Disallow: /feed/
Disallow: /comments/
Disallow: /category/*/*
Disallow: */trackback/
Disallow: */feed/
Disallow: */comments/
Disallow: /*?
Allow: /wp-content/uploads/
Not to argue with the developers, but I did want to get more examples and opinions from others. I found many other similar configurations with some slight differences. There really isn’t a right way to configure this, it’s just your preferences and what works best for you. This can always be changed, it’s not written in stone once you save it. I say play around with it and check in to your Google Developers page often – to see if there are any crawler errors. Here’s my robots.txt file that has been working great for me.
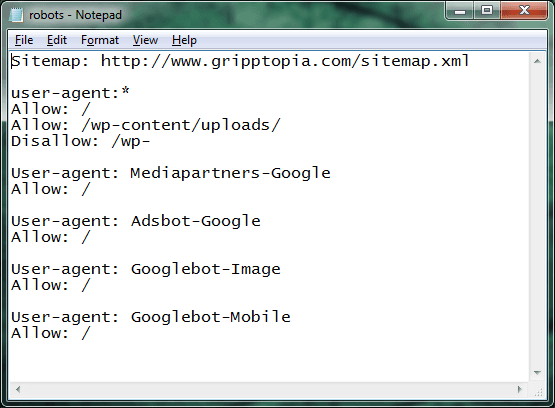
Sitemap: https://gripptopia.com/sitemap.xml
user-agent:*
Allow: /
Allow: /wp-content/uploads/
Disallow: /wp-User-agent: Mediapartners-Google
Allow: /User-agent: Adsbot-Google
Allow: /User-agent: Googlebot-Image
Allow: /User-agent: Googlebot-Mobile
Allow: /
Other Notes
At one time, I didn’t have the Google agents added in. Since I have added these, there have been little to no crawler errors.
Since I was blocking /wp- I had made the mistake of not allowing the wp-content/uploads/ directory – which withheld almost all of my site’s images from search engines. Not good!
If you are unsure how to create a robots.txt for your website, check out How to Create Or Edit Robots.txt.
LOL… thank you for this post. I have a really good site with over 200+ posts and just found out my WHOLE STRUCTURE WAS TRASH! This was one of the elements I was missing for sure. Appreciate it! :)
Better late than never – to discover something like that. Glad I could help.